AI算力平台服务
算力平台服务
NVIDIA DGX™ A100 是适用于所有 AI 工作负载的通用系统,为全球首款 5 petaFLOPS AI 系统提供超高的计算密度、性能和灵活性。采用全球超强大的加速器 NVIDIA A100 Tensor Core GPU,可让企业将深度学习训练、推理和分析整合至一个易于部署的统一 AI 基础架构中,该基础架构具备直接联系 NVIDIA AI 专家的功能。

一、功能强大的 DGX A100 组件
1) 八块 NVIDIA A100 GPU,GPU 总显存高达 320 GB,每块 GPU 支持 12 个 NVLink 连接,GPU 至 GPU 带宽高达 600 GB/s;
2) 六个第二代 NVSWITCH,双向带宽高达 4.8 TB/s,比上一代产品高出 2 倍;
3) 九个 Mellanox ConnectX-6 VPI HDR InfiniBand/200 Gb 以太网双向带宽峰值高达 450 GB/s;
4) 两块 64 核 AMD CPU 和 1 TB 系统内存,以 3.2 倍核心数量满足超密集的 AI 作业;
5) 15 TB 第四代 NVME SSD,带宽峰值高达 25 GB/s,比三代 NVME SSD 快两倍。
无锡开悟基于NVIDIA DGX A100服务器集群技术建立起AI数据中心,面向AI企业、科研机构、创业团队等人工智能行业从业者,以极其具有竞争力的价格,提供全球最先进的AI算力资源, 协助其进行人工智能技术解决方案、深度模型的训练和算法研发。
二、划时代的性能
1. 分析
PageRank
更快的分析意味着对 AI 开发有更深入的见解
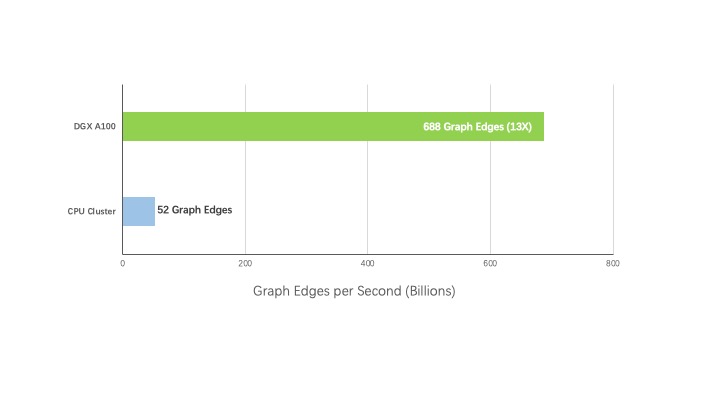
性能对比
3000X CPU Servers vs.4X DGX A100.Published Common Crawl Data Set: 128B Edges,2.6TB Graph.
2. 训练
NLP: BERT-Large
更快的训练速度带来更先进的 AI 模型
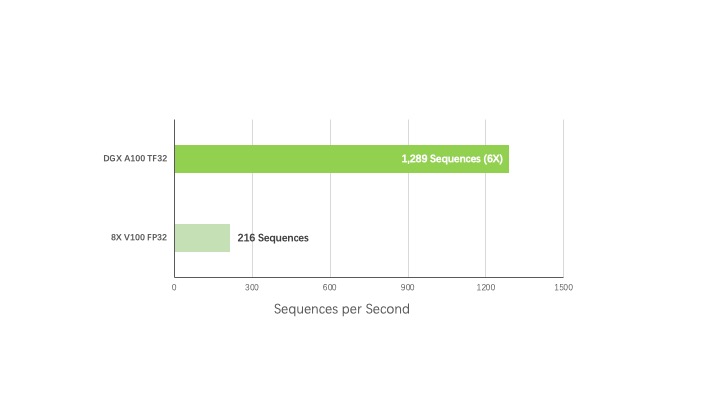
性能对比
BERT Pre-Training Throughput using PyTorch including (2/3) Phase 1 and (1/3) Phase 2.
Phase 1 Seq Len=128, Phase 2 Seq Len=512.
V100: DGX-1 with 8X V100 using FP32 precision.
DGX A100: DGX A100 with 8X A100 using TF32 precision.
3. 推理
Peak Compute
更快的推理通过最大化系统利用率提高投资回报率

性能对比
CPU Server:2X Intel Platinum 8280 using INT8.
DGX A100 with 8X A100 using INT8 with Structural Sparsity.
三、使用AI数据中心算力你将体验到
各种AI工作负载的通用系统
DGXperts:集中获取AI专业知识
更加快速的体验
卓越的可扩展性